Fast Food Unhealthiness vs Popularity Analysis
Analyzed whether more unhealthy fast food menus are associated with higher popularity. Combined nutritional data with sales and store metrics to explore how health and business success relate across major U.S. fast food chains.
More details
Problem
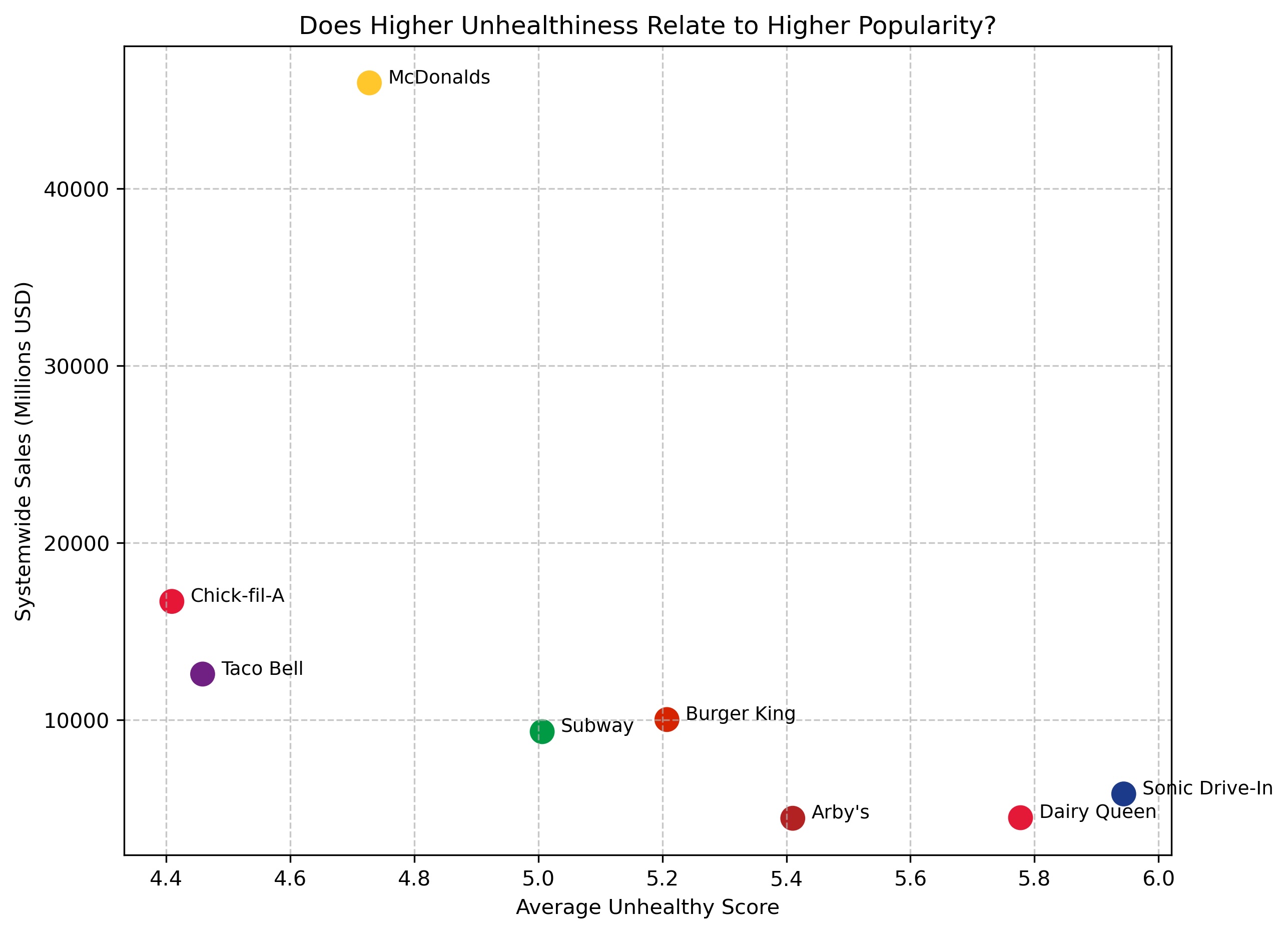
Fast food is widely consumed, but it is unclear whether unhealthier menus actually drive greater popularity. This project investigates whether chains with higher calorie, fat, and sodium content tend to generate more revenue and market presence.
Approach
Merged nutritional data with business metrics such as systemwide sales, average sales per unit, and total store count. Created a custom unhealthy score and used visualizations to compare nutrition patterns with popularity indicators.
Results & Impact
The analysis showed that there was no perfect relationship between unhealthiness and popularity. McDonald's had the highest sales without being the most unhealthy, suggesting that branding, accessibility, and pricing also influence success.

